
A comprehensive system built on a sophisticated knowledge graph that captures the full breadth of e-commerce concepts – tackles e-commerce challenges through user need analysis and cohesive system design. The platform architecture and audit processes can be elevated through machine learning (ML), artificial intelligence (AI), and the latest large language models (LLMs) such as o1 and Gemini, all made possible by the collaborative efforts of product, operations, and engineering teams.
From its inception, the specialized design of an e-commerce knowledge graph has played a critical role in accommodating the diverse requirements of large-scale e-commerce operations. There is a significant opportunity to expand data cognition, semantic comprehension, and personalized user engagement to new heights.
Why E-Commerce Knowledge Graphs Are More Relevant Than Ever
As e-commerce organizations continue to expand the boundaries of their business units and reimagine what Internet and cloud technologies can do, data interconnection is growing at a striking rate. Data, or more precisely, connecting the dots between data points, plays a crucial role in search and discovery, shopping guides, and overall platform user interaction. Above all else, intelligently using data is fundamental to improving the user experience.
A knowledge graph is an excellent way to aggregate, structure, and interpret large volumes of data spanning multiple domains. Before diving into how our new knowledge graph works—particularly with LLM-driven enhancements—let’s consider the key problems that led to its creation:
- Massive, Unstructured Data: E-commerce data arrives from multiple distributed sources and includes queries, product titles, images, videos, and user comments—much of which is unstructured.
- High Noise Levels: User-generated data (e.g., queries, titles, comments) contain heavy noise. This makes traditional text analysis less effective without sophisticated ML and AI to filter the “dirty” data.
- Multi-Modal and Multi-Source Complexity: E-commerce data now comprises text, images, video, and more, requiring specialized methods to link and interpret these diverse inputs.
- Data Fragmentation: Different departments often maintain disparate category-property-value (CPV) systems. This leads to repeated efforts for classification and search.
- Insufficient Deep Data Cognition: Beyond items, deep cognition must associate user needs across multiple domains. For example, identifying whether a user is preparing for pregnancy by analyzing behaviors and searches (e.g., “folic acid”) requires advanced reasoning—precisely the sort of task that new LLMs can excel at.
What the Framework Needs to Do
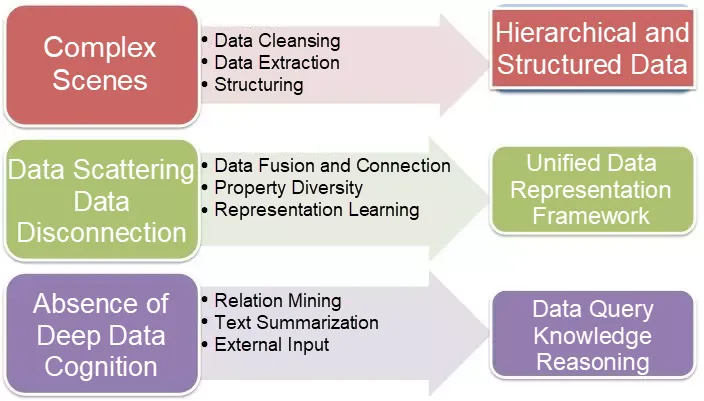
To address these challenges, the knowledge graph framework must:
- Structure Data in Complex Scenes: First, cleanse the data via frequency-based filtering, rules, and statistical analysis. Then apply methods such as phrase mining and entity extraction to build a hierarchical structure.
- Provide a Unified Representation Framework: Define a global schema representation to merge conceptual data. Use relationship extraction, data mining, and knowledge representation techniques to link data at scale.
- Enable Deep Data Cognition: By examining user behaviors, items, and external data, recognize deeper user intentions and more complex relationships between concepts. LLMs can now interpret and infer more subtle semantic links than before.
Introducing Our E-Commerce Knowledge Graph
To solve the above problems, we have created an E-commerce KG, aiming to establish a unified knowledge system for the e-commerce domain. It covers users, items, scenes, and even external data in one coherent framework. Our vision is to interlink users, items, and scenarios to empower the diverse business lines—ranging from online retail to second-hand marketplaces—by deeply cognizing user needs.
Module Division
E-commerce ConceptNet is divided into four key modules:
- User Graph Construction
Contains user-group data (e.g., “users who are parents” or “young professionals”), plus user profile information (age, gender, purchasing power, category preferences). - Scene Graph Construction
A scene is an abstraction of user needs. By generalizing user needs from queries and product titles into higher-level concepts (e.g., “outdoor barbecue,” “holiday outfits”), we can capture cross-category links and unify them into a scene concept. - Category Refinement
- Category Aggregation: Some categories appear in multiple top-level domains (e.g., “dress” in both “women’s wear” and “children’s wear”). A more generalized common-sense approach is needed to unify them.
- Category Splitting: Sometimes an existing category is too broad. For example, in “traveling in Tibet,” a specialized subcategory like “windproof scarf” may be needed.
- Item Graph Construction
- Phrase Mining: Identify significant phrases and terms for robust CPV systems.
- Item Tagging: Tag items with relevant concepts and properties to complete the link between queries and products.
How LLMs Enhance These Modules
Traditional NLP pipelines (e.g., word segmentation, part-of-speech tagging, entity linking) have formed the backbone of knowledge graph construction. However, LLMs now offer more powerful semantic understanding, enabling:
- Richer Entity Extraction: LLMs can parse noisy user-generated text more accurately, identifying nuanced attributes (e.g., “scratch-resistant watch bands,” “windproof scarves”) in one pass.
- Contextual Disambiguation: Where item or category names overlap (e.g., “dress” for womenswear vs. children’s wear), LLMs can understand context from user or scene data.
- Multi-Modal Interpretation: Advanced LLMs, combined with vision-language models (if integrated), can interpret images, product videos, and textual descriptions together, improving recommendation accuracy.
- Conversational Query Understanding: Tools like chatbots and voice interfaces can parse user questions (e.g., “I need something for a windy trip to Tibet”) and directly map them to scene graphs.
With this approach, the entire knowledge graph pipeline—from ingestion to item tagging—becomes more robust, delivering better recall and precision in real-world e-commerce scenarios.
To provide a scalable, cloud-native infrastructure, we leverage AWS services for data storage, processing, and ML integration:
- Data Storage and Ingestion
- Amazon Simple Storage Service (Amazon S3): Staging area for large volumes of raw text, images, videos, and logs.
- AWS Glue: Automates ETL (extract, transform, load) jobs, cleaning and normalizing raw data before it’s moved into analytics or graph databases.
- Knowledge Graph Engine
- Amazon Neptune: A fully managed graph database service used for storing the e-commerce knowledge graph (concepts, relations, item tags). Neptune supports Gremlin and SPARQL queries, facilitating flexible and high-performance graph traversals.
- Amazon RDS or Amazon DynamoDB: Depending on the design, certain structured elements can be held in relational (RDS) or NoSQL (DynamoDB) formats for quick lookups.
- Big Data Analytics and Processing
- Amazon EMR (Elastic MapReduce): For large-scale data processing using Hadoop/Spark.
- Amazon Athena: For interactive querying of data in S3 using standard SQL.
- Amazon Kinesis: For real-time data streams (e.g., user clicks, purchase logs) that can feed into the knowledge graph.
- LLM Deployment and Inference
- Amazon SageMaker: Enables training, fine-tuning, and deploying advanced LLMs (like o1 and Gemini if provided as containerized models or through custom frameworks). SageMaker can also host custom inference endpoints for NLP tasks such as entity recognition, text classification, and summarization.
- AWS Inferentia (EC2 Inf Instances): Specialized instance type for high-performance, cost-effective inference on large models.
- Application Layer
- API Gateway and AWS Lambda: For serverless and scalable microservices that interface with front-end applications (e.g., for user personalization, product recommendations, or search).
- Amazon CloudFront: Provides low-latency content delivery for global user bases, essential for e-commerce sites with international reach.
Technical Details and Workflow
- Data Collection & Cleansing
- Raw data—queries, item titles, user interactions—flows into Amazon S3.
- AWS Glue cleanses data, filtering out noise using frequency-based methods and rules.
- Phrase Mining & Schema Building
- Spark on Amazon EMR identifies frequent, domain-specific terms.
- The refined CPV data is stored in Neptune as node and relationship tables.
- Concept & Scene Graph Construction
- LLM-based Extraction (o1/Gemini): Automatic classification of scenes (e.g., “outdoor barbecue,” “holiday outfits”) by analyzing top queries and item descriptions.
- Scenes are linked to relevant categories and items using Neptune’s graph structure.
- Item Tagging & Categorization
- After the phrase mining and concept extraction phase, items are automatically tagged in Neptune.
- Fine-grained category prediction improves with LLM-based classification.
- Real-Time Query & Recommendation
- Using AWS Lambda & Amazon API Gateway, front-end services can query Neptune to fetch relevant items.
- LLM inference (on SageMaker) can refine user queries to ensure accurate retrieval and personalized suggestions.

Early Results and Future Directions
- Pilot Launch: By deploying an initial version of item tagging in Neptune, we have already seen improvements in query coverage and click-through rates. For instance, the percentage of queries fully recognized rose from 30% to 60% in early tests.
- Enhanced Diversity in Recommendations: Leveraging knowledge cards (like “scenes” or “concept bundles”) has increased item diversity in recommended lists, improving user engagement.
Next Steps
- Relationship Mining & Ontology Construction: Continuous enhancement of concept hierarchies and relationship extraction, powered by advanced LLM fine-tuning.
- Data Augmentation: Integrating external knowledge sources (e.g., public concept nets, brand dictionaries) and user feedback loops.
- Common-Sense Reasoning: Developing logical reasoning rules to infer implicit user needs (“preparing for a baby,” “looking for sustainable products,” etc.).
- Symbolic & Neural Hybrid Reasoning: Combining symbolic graph-based approaches with neural methods from LLMs for even deeper semantic understanding.
By building on AWS and integrating cutting-edge LLMs such as o1 and Gemini, we’re poised to deliver smarter, more personalized, and scalable e-commerce experiences. From noise reduction to multi-modal data interpretation, the synergy of a robust knowledge graph and advanced AI ensures that online shopping platforms can keep evolving to meet the dynamic needs of users around the globe.